Non-Linear ADP Controller¶
The below algorithms is given in the book Robust Adaptive Dynamic Programming.
Problem statements¶
Given the nonlinear system equation (2), design a control policy  that minimize the following cost function:
that minimize the following cost function:
(1)¶
where  with
with  a positive definite function, and
a positive definite function, and  is symmetric and positive definite for all
is symmetric and positive definite for all 
If there exists a feedback control policy  that globally asymtotically stabilizes the system (2) at the origin and the associated cost as defined in (1) and there exists a continous differentiable function
that globally asymtotically stabilizes the system (2) at the origin and the associated cost as defined in (1) and there exists a continous differentiable function  such that the Hamilton-Jacobi-Bellman (HJB) equation holds
such that the Hamilton-Jacobi-Bellman (HJB) equation holds  then the control policy
then the control policy
(2)¶
globally asymptotically stabilizes (2) at  , and
, and  is also the optimal control policy
is also the optimal control policy

Off Policy Learning¶
Consider the system with the folowing control policy
(3)¶
where u0 is the initial admissible control policy and  is the
is the exploration noise then rewrite it as
(4)¶
where  .
.
Take the time derivative of  along (4) and integrate the result within interval
along (4) and integrate the result within interval ![[t,t+T]](_images/math/47bce94d7bc2b2d51b198ea846de5a8932eeec46.svg) to obtain:
to obtain:
(5)¶![V_i(x(t+T)) - V_i(x(t)) = - \int_t^{t+T} [q(x)+u_i^TRu_i + 2u_{i+1}^TRv_i]d\tau](_images/math/fa9e9bede9bb03f1ae213a486dd1e722cb7e1438.svg)
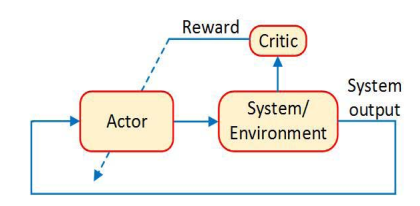
Because the formula (2) requires the knowledge of the dynamic of the system, it makes practical application limited. One may use neural networks to approximate the control policy  (the
(the actor)and the unknown cost function (the critic).

where  and
and  are two sequences of linearly independent smooth basis function,
are two sequences of linearly independent smooth basis function,  is the weight of the neural networks.
is the weight of the neural networks.
Replacing them to the (5) and transform the result into the matrix, we have
(6)¶
where  and the same for
and the same for  and
and

Finally, one can realize that the (6) is actually a fixpoint equation in the form

Note
the initial controller
u0must beadmissiblecontrollerthe squences of basis functions
 should be in the form of linearly independent smooth. Default basis functions is the
should be in the form of linearly independent smooth. Default basis functions is the polynomial functions, seeOpenControl.ADP_control.NonLinController.default_psi_func()andOpenControl.ADP_control.NonLinController.default_phi_func()the time interval
Tfor data collection must be larger than the sample timenumber of data
the default function
is 
Algorithm¶
Library Usage¶
Define a non-linear system like in System representation, then setup a simulation section by OpenControl.ADP_control.NonLinController.setPolicyParam() and perform simulation by OpenControl.ADP_control.NonLinController.offPolicy()
from OpenControl.ADP_control import NonLinController
##########define a controller##################
Ctrl = NonLinController(sys)
u0 = lambda x: 0 # the system is already globally stable
data_eval = 0.01; num_data = 80 # at leats n_phi+n_psi
explore_noise = lambda t: 0.2*np.sum(np.sin(np.array([1, 3, 7, 11, 13, 15])*t))
###############setup policy parameter############
Ctrl.setPolicyParam(data_eval=data_eval, num_data=num_data, explore_noise=explore_noise, u0=u0)
###############take simulation step##############
Wc, Wa = Ctrl.offPolicy()
then the optimal control policy is given by
uopt = lambda t,x: Wa.dot(Ctrl.psi_func(x))