Linear ADP Controller¶
The below algorithms is given in the book Robust Adaptive Dynamic Programming.
Problem statements¶
Given the linear system equation (1), design a linear quadratic regulator (LQR) in the form of  that minimizes the following cost function
that minimizes the following cost function

where  .
.
The solution of this problem is  which is also the solution of the Riccati equation, can be obtained by
which is also the solution of the Riccati equation, can be obtained by OpenControl.ADP_control.LTIController.LQR(). However, this approach requires the knowledge of the system dynamic (the matrix A and B). The model-free approach below will resolve this problem.
Lets begin with another control policy  where the time-varying signal e denotes an artificial noise, known as the
where the time-varying signal e denotes an artificial noise, known as the exploration noise. Taking time derivative of the cost function and integrate it within interval ![[t,t+\delta t]](_images/math/b06b5b2de46fed550dff3eb14ade14de536f4f57.svg) to obtain:
to obtain:
(1)¶
 .
.On-policy learning¶
For computational simplicity, we rewrite (1) in the following matrix form:
(2)¶
where

Note
To adopt the persistent excitation condition, one must choose a sufficiently large
number of data to satisfy the following condition:
to satisfy the following condition:

In practical,

The time interval for each learning section is
 , so properly set
, so properly set OpenControl.ADP_control.LTIController.num_dataandOpenControl.ADP_control.LTIController.data_evalto make sure the learning section not too slow
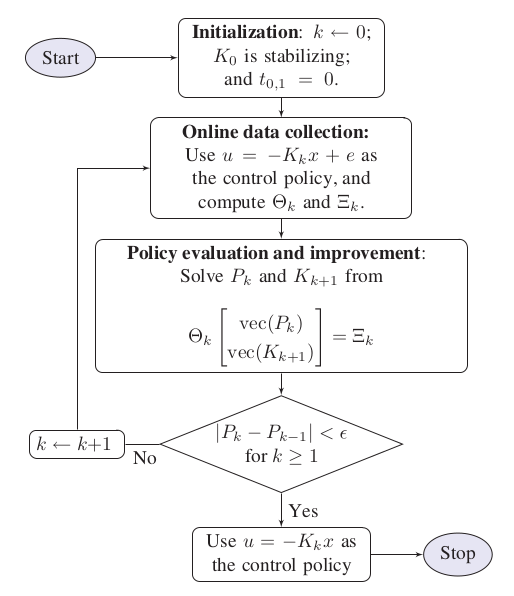
Algorithm¶
Library Usage¶
Setup a simulation section with OpenControl.ADP_control.LTIController and OpenControl.ADP_control.LTIController.setPolicyParam() then perform simulation by OpenControl.ADP_control.LTIController.onPolicy()
from OpenControl.ADP_control import LTIController
Ctrl = LTIController(sys)
# set parameters for policy
Q = np.eye(3); R = np.array([[1]]); K0 = np.zeros((1,3))
explore_noise=lambda t: 2*np.sin(10*t)
data_eval = 0.1; num_data = 10
Ctrl.setPolicyParam(K0=K0, Q=Q, R=R, data_eval=data_eval, num_data=num_data, explore_noise=explore_noise)
# take simulation and get the results
K, P = Ctrl.onPolicy()
Off-policy learning¶
Let define some new matrices

and  defined by:
defined by:

then for any given stabilizing gain matrix  , (1) implies the same matrix form as (2)
, (1) implies the same matrix form as (2)
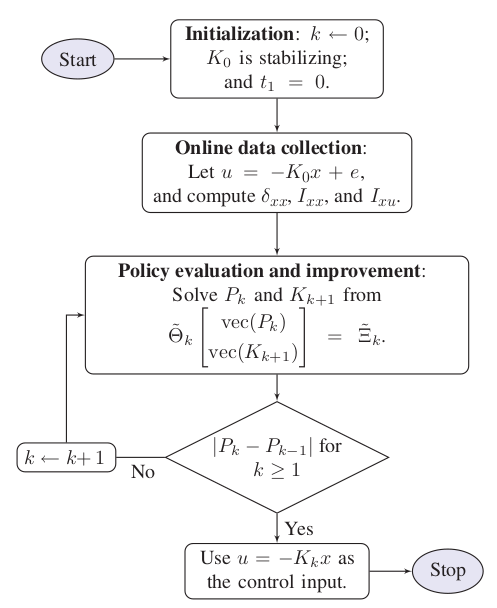
Algorithm¶
Library Usage¶
Setup a simulation section the same as the section then perform simulation by OpenControl.ADP_control.LTIController.offPolicy()
K, P = Ctrl.offPolicy()